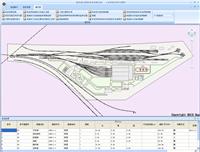
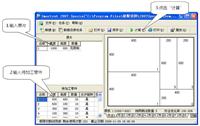
重磅!Stata 18正式发布!
- 时间:2023-04-26作者:北京友万信息科技有限公司浏览:246
一直以来,我们坚持产品质量**,对产品投入高新科技,不断增加研发人员来开发新产品,以满足客户的需要。到目前为止,我们公司已经研发出了多个系列激光灯:单投、双投、动画和满天星。所有的激光灯都通过了CE、ROHS和FDA认证。激光灯可以广泛的应用于DJ、迪斯科舞厅、KTV、家庭舞会、夜总会、娱乐圈、贸易展示、博览会、电影院、宣传公司Logo等许多场合,为人们的娱乐生活添姿添彩。深圳市奥朗特科技有限公司坚持以诚信、务实、开拓、创新为宗旨;以市场、消费者的实际需求为导向,实施品牌和CS经营战略,把向消费者提供高质量产品、优质服务、优惠价格和快速运输作为公司的发展宗旨。我们真诚希望与**各界共同合作,共同发展。
公司地址:深圳市龙华大浪部九窝金西城大厦四楼
深圳市奥朗特科技有限公司
北京友万信息科技有限公司专注于Minitab,Stata,SPSS等, 欢迎致电 18600528290
词条
词条说明
2023年1月4日-6日,由北京友万信息科技有限公司主办,顺德职业技术学院承办的,为期三天的“Python数据分析内训课程”圆满结束。本次课程受环境因素影响依旧采用线上直播的方式进行。但是这并不影响顺德职业技术学院老师们的学习热情。此次培训为顺德职业技术学院内部定制的高级培训课程,共有五十余人参加,课程内容和效果也受到了参培人员的一致好评。主办方北京友万信息科技有限公司为参培人员提供了全部的内训课
为了确保学术研究的科学性和可靠性,《管理世界》编辑部近日公布了一项重要新规。从2023年9月10日开始,所有投稿日期在此日期及以后的文章,如果通过终审,作者需要在收到《论文拟录用通知》后的10天之内,在投稿系统中以附件形式上传数据、程序代码、实截图、方法说明等资料。这一新规定凸显了学术研究对数据和程序代码的重视,因为这些资料对于验研究的可靠性和复制研究具有至关重要的作用。同时,这也是《管理世界》编
Python作为一门面向多对象的编程语言,简洁的语法使得编写数十行代码即可实现各种数据分析功能。在研究海量数据时使用Python加简单且效率高的处理分析数据。随着数据时代的到来,越来越多的学校开设Python课程,除了学生,老师也开始加精益的要求提高自己的教学水平和科研水平。2023年1月31日-2月2日,由北京友万信息科技有限公司主办,佛山科学技术学院承办的,为期三天的“Python数据分析
2023年 Minitab 统计分析在线免费网络研讨会 ( 第七期 ) 《试验设计II》成功举办 !
2023 年友万科技全程主办九期的“Minitab统计分析在线免费网络研讨会”第七期于 9 月 12 日成功开播!2022 年 1 月 1 日,北京友万信息科技有限公司荣幸地宣布与 Minitab, LLC(数据分析、预测分析和过程改进领域的市场领导者)建立新的合作伙伴关系,成为 Minitab, LLC中国教育领域核心代理。为了让更多的教育用户体验Minitab带来的科研魅力,2022年我们规划
联系方式 联系我时,请告知来自八方资源网!
公司名: 北京友万信息科技有限公司
联系人: 陈
电 话:
手 机: 18600528290
微 信: 18600528290
地 址: 北京昌平城南中兴路21号院硅谷SOHO C-516
邮 编:
网 址: uonetech.b2b168.com
相关推荐








相关阅读
1、本信息由八方资源网用户发布,八方资源网不介入任何交易过程,请自行甄别其真实性及合法性;
2、跟进信息之前,请仔细核验对方资质,所有预付定金或付款至个人账户的行为,均存在诈骗风险,请提高警惕!
- 联系方式
公司名: 北京友万信息科技有限公司
联系人: 陈
手 机: 18600528290
电 话:
地 址: 北京昌平城南中兴路21号院硅谷SOHO C-516
邮 编:
网 址: uonetech.b2b168.com
- 相关企业
- 长沙群力测绘科技有限公司
- 安徽靓马信息科技股份有限公司
- 合肥安图经纬测绘有限公司
- 合肥宇陆勘测设备有限公司
- 合肥国观测绘工程有限公司
- 合肥瑞利达电气技术有限公司
- 甘肃天慧遥感信息技术有限公司
- 莆田市山海测绘技术有限公司城厢分公司
- 河南省恒信工程技术服务有限公司
- 黑龙江润利测绘有限公司
- 商家产品系列
- 3d操控器
- 3d打印机
- adsl
- av音箱
- av音响
- combo
- cpu
- crt显示器
- dv摄像带
- gps
- HiFi音箱
- hifi音响
- ip集团电话
- IP网络存储
- it
- kvm切换器
- led数码管
- LED显示设备
- 等离子电视
- 地理信息系统
- 点钞机
- 点读机
- 点歌系统
- 电饼铛
- 电吹风
- 电磁炉
- 电动牙刷
- 电饭煲
- 电风扇
- 电话会议
- 产品推荐
- 资讯推荐

¥360.00

¥500.00




¥1.00